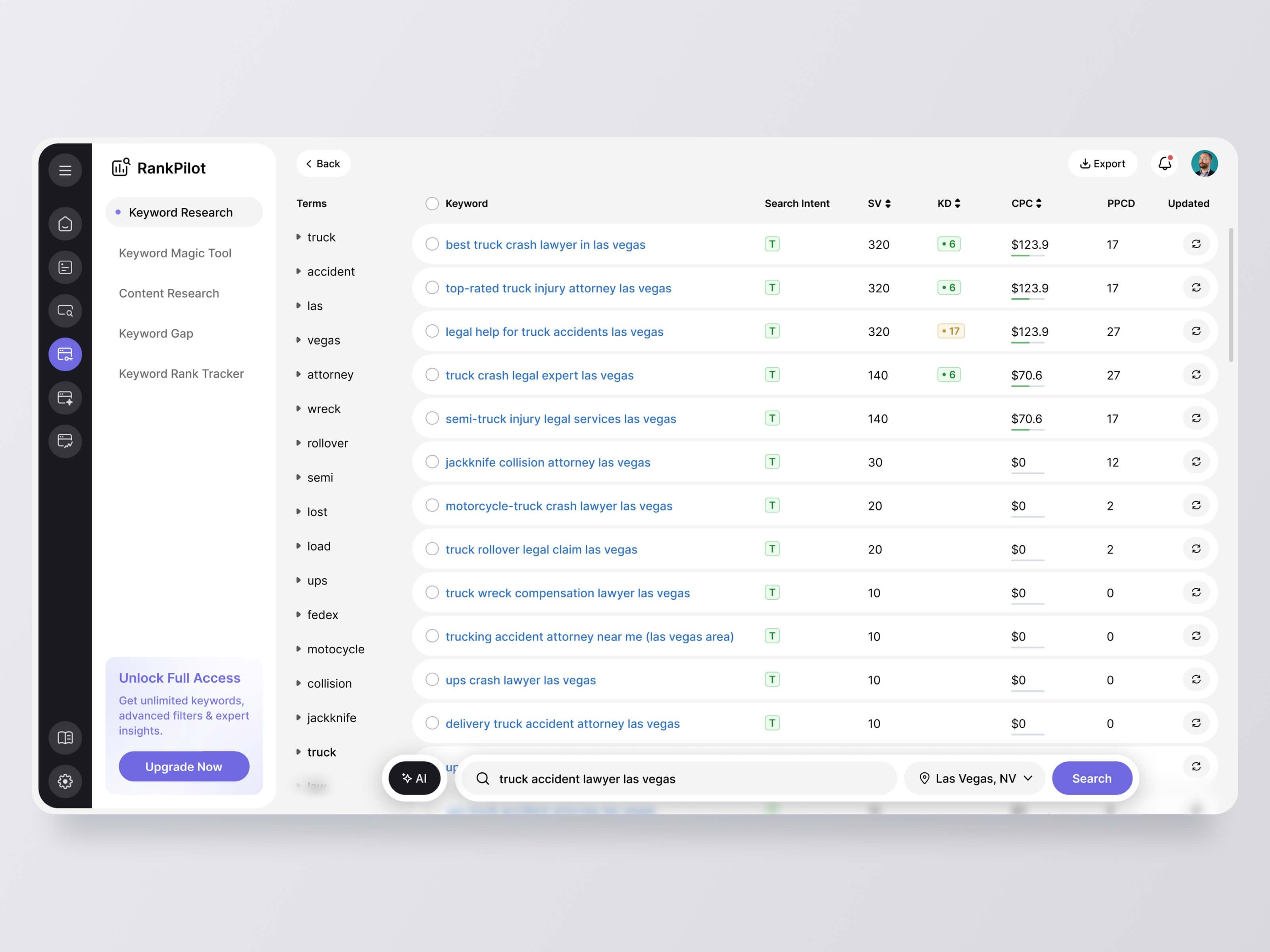
Marcus built 800 location pages in a weekend. He had a spreadsheet of cities, a Python script that hit GPT-4, a simple template for each page, and a Cloudflare Worker that published the output straight to his CMS. By Sunday night the site had gone from 40 pages to 840 pages. By Monday morning he had submitted the sitemap. By Tuesday he was watching impressions climb in Search Console.
He thought he'd cracked it.
For two months, he kind of had. Rankings came in fast. Local terms for service-area cities he'd never targeted before started showing up. Traffic went from 3,000 monthly visitors to nearly 18,000. He told his co-founder this was the growth loop they'd been looking for. He started planning the next batch. Maybe 2,000 pages this time. Maybe 5,000. The script could handle it. The cost per page was something like $0.08. The math felt impossible not to do.
Then Google pushed the Helpful Content Update.
of Marcus's organic traffic evaporated within three weeks of the HCU rollout — not gradual, a cliff
Not a rumor. Not speculation. The actual update that specifically targeted what Google called "content made primarily to rank in search engines rather than for people." Within three weeks of the rollout, Marcus's site lost 70% of its organic traffic. Not gradually. A cliff. The kind that makes you check if your hosting is still up.
He went through all the usual stages. Checked for technical issues. Filed a Search Console investigation request. Read every SEO forum thread he could find. Paid for two separate SEO audits. Both audits said the same thing: the content was thin, templated, and lacked signals of genuine expertise or real usefulness to the person reading it. The pages about Austin had the same structure as the pages about Tucson. The paragraphs were different words that said the same things. Google's classifier had seen through it.
What Marcus didn't know was that the fix wasn't to stop using AI. The fix was humanization. Not just running the content through a spinner or swapping synonyms. Actual humanization — the kind that changes the quality signals the text emits, adds genuine variation between pages, and makes each page feel like a person who cared about that specific location had written it.
⚠️This is not a 'don't use AI' warning
This guide is not telling you to write 800 pages by hand. It is telling you that AI-generated content published without humanization has predictable failure modes that a proper pipeline eliminates. The economics of programmatic SEO are real. You just need the right workflow.
What Programmatic SEO Is and Why AI Content Wrecked It
Programmatic SEO is the practice of building large numbers of pages at scale using templates populated with structured data. Instead of writing each page individually, you define a template with variable slots, connect it to a data source, and generate pages in bulk. The classic example is Zapier's integrations directory: tens of thousands of pages like "Connect Slack to Gmail" or "Sync HubSpot with Notion," each generated from the same underlying template with different app-pair data filling the variables.
Before AI writing tools, programmatic SEO had a natural quality floor. The data had to be real. The template had to be built thoughtfully. And even with good data, the content on each page tended to be sparse because filling those variable slots with genuine written text was expensive and slow. The practical ceiling for most teams was a few thousand pages, and only the ones with large datasets and engineering resources could get there.
Then AI writing tools arrived and that natural ceiling disappeared. The cost per page dropped from something like $8 to something like $0.05. The time per page dropped from 30 minutes to 1.2 seconds. Teams that previously couldn't justify 500 pages suddenly had no technical or economic barrier to 50,000 pages.
Google noticed. Of course they noticed. The Helpful Content Update was Google's response. First announced in August 2022, then iterated heavily through 2023 and folded into Google's core ranking systems in 2024, the HCU fundamentally changed how Google evaluates content at the site level. It introduced what Google calls a "site-wide signal" for unhelpfulness. If a significant portion of your site's pages are classified as unhelpful, that classification affects the ranking ability of every page on the domain. Not just the bad pages. The whole site.
Our systems automatically identify content that seems to have little value, low-effort, or is not particularly helpful to those doing searches. Any content not helpful could affect a site's performance in Google Search.
This is the part that catches people. They think Google penalizes individual bad pages. For normal quality issues, that's true. But with the Helpful Content system, publishing a lot of low-quality programmatic pages doesn't just hurt those pages. It contaminates the site-level quality signal and reduces the ranking potential of your best content too. A site with 200 excellent blog posts and 5,000 thin AI-generated city pages can see its blog traffic collapse even though the blog posts themselves are genuinely good.
🔑The core problem with unhumanized programmatic content
AI-generated programmatic content fails Google's helpful content evaluation because it is optimized for keyword coverage, not user satisfaction. The text is technically coherent but informationally hollow. Humanization changes the content's relationship to the user's actual need — that is what makes it survive.
Detection Reality
The question people ask is: does Google actually detect AI content? The answer is more nuanced than a simple yes or no. Google does not primarily penalize content for being written by an AI. Google penalizes content for being low quality. The two overlap heavily because most AI-generated content at scale is low quality. But they are not the same thing, and understanding the difference changes how you approach humanization.
The Content Quality Signals Google's Classifier Uses
Google's quality evaluators look at a set of signals that, taken together, determine whether a page provides genuine value. These include: the specificity of information relative to the claimed topic, the presence of original data or analysis that couldn't be copy-pasted from another source, the structural relationship between the page's declared focus and its actual content, the presence of named entities with correct context, and the consistency between what the page promises in its title and what the page actually delivers.
For programmatic pages, the specificity signal is the one that kills most of them. An AI-generated page about "best restaurants in Denver" written from a template produces text that is about Denver in the same way that a horoscope is about you personally. It sounds specific. It names Denver. It uses Denver-related language. But it doesn't actually contain the kind of knowledge that only comes from knowing Denver. There's no mention of LoDo specifically being where most of the food scene clusters. No reference to the altitude affecting cooking. No specific restaurants with real data behind them. The text is Denver-flavored generality, and classifiers trained on the difference between genuine local knowledge and template-filled content have learned to see through it.
Pattern Recognition on Programmatic Page Structures
Google's crawlers process the structure of pages across your entire domain simultaneously. They can identify when multiple pages share the same structural DNA — identical heading hierarchies, the same paragraph count per section, the same word count range, the same content-to-template ratio. This structural pattern recognition is separate from the content quality evaluation and can flag a site as programmatic before any individual page quality assessment even happens.
The tell is variation. Genuine content, even content about similar topics from the same author, varies organically. Paragraph lengths differ. Section structures shift. Some pages are longer because the topic demands it. Others are shorter. Programmatic templates tend to produce suspiciously consistent page sizes and structures because they're all built from the same scaffold.
The Site-Level Sampling Google Uses
When Google evaluates a domain that has published large numbers of pages in a short period, they don't evaluate every single page individually at first. They sample. Crawlers hit a representative cross-section of the new pages, the quality classifier runs on that sample, and if the sample quality falls below threshold, a site-wide signal gets applied. This is how 800 pages published over a weekend can trigger a domain-level penalty within weeks even though Google hasn't fully indexed all of them yet. The sample failed. The whole domain pays.
Programmatic SEO penalty-era signals
| Signal | Value | What it means |
|---|
| HCU traffic loss | 60-80% | Typical drop for sites with high-volume AI programmatic content |
| Google's sample size | ~50 pages | Pages sampled from a new batch to evaluate site quality |
| Recovery timeline | 6-18 months | Time for a domain to recover after HCU with aggressive remediation |
| Thin-page threshold | ~30% | Proportion of unhelpful pages that starts affecting site-level signal |
Knowing what Google is looking for is half the battle. The other half is building pages that actually possess those signals. Not faking them. Possessing them.
E-E-A-T at the Page Level for Programmatic Content
Experience, Expertise, Authoritativeness, Trustworthiness. Google added the first E for Experience to signal that first-hand experience with a topic is now a ranking signal. For programmatic content, this creates an interesting challenge: how do you signal first-hand experience on a page about plumbers in every city in America? You don't fake it. You build it in through data. Real pricing ranges sourced from real quotes. Real response times from real service records. Real customer review aggregation from real review sources. The experience signal comes from the data layer of your programmatic content, not from the written prose alone.
Unique Data Inclusion: The One Signal That Matters Most
This is the highest-leverage quality signal for programmatic content. If your pages contain data that cannot be found on a thousand other websites — data that is specific to the entity being discussed and was gathered or compiled specifically for this page — the page has a defensible quality floor that templates without unique data simply cannot match.
Unique data means: real pricing from real vendors, real review scores pulled from real review platforms, real geographic data that corresponds to the actual location, real business information from real business records. It is the difference between a travel page that says "San Antonio has a vibrant tourism scene" and one that says "Downtown San Antonio had 14.9 million visitors in 2024, concentrated around the River Walk which extends 15 miles through the city center."
For most programmatic content operators, the practical solution is to build a real data layer before you build your templates. Scrape or purchase the data you need. Build a database of unique facts for each entity. Then write templates that pull from that database in ways that produce genuinely different pages. The humanization layer then transforms that data-rich template output into natural text. That is the pipeline that works.
User Engagement Signals Google Is Watching
Google uses engagement signals from Chrome data and Search Console click behavior to refine quality evaluations post-publish. Pages with high bounce rates, very short dwell times, and immediate back-navigation to the search results page send negative engagement signals. For programmatic content, this is the moment of truth. A page can fool a classifier on initial evaluation but if users consistently arrive and leave within 10 seconds, the engagement signal confirms the quality problem.
💡The two-tier content test
Before publishing a batch of programmatic pages, ask: (1) Does each page contain at least one piece of data that is specific to that entity and cannot be found on a generic competitor page? (2) Would someone who lives in or knows about that location recognize the page as being specifically about their location? If both answers are yes, you have a foundation. If either is no, humanization alone won't save the page.
The Workflow
Here's the thing most people get wrong: they think humanization is a finishing step. A polish pass. Something you run at the end to "make it sound more human." It's not. Humanization for programmatic SEO at scale is a systems design decision that touches the architecture of your entire pipeline from data layer to published page.
Why Every Page Can't Be Manually Humanized
The economics of programmatic SEO are built on the assumption that the cost per page is low. If you're publishing 2,000 pages, manually humanizing each one at $5 per page is $10,000. At that cost, the ROI calculation breaks for most businesses. The whole point is scale. So the humanization workflow has to be automated or at least semi-automated.
This is where humanizer APIs become the correct tool. Not a consumer-facing humanizer tool that you paste text into one at a time. An API that you call programmatically as part of your content pipeline, that processes text at scale and returns humanized output that passes quality evaluation.
The Tiered Humanization Approach
Not all programmatic pages have the same stakes. A tiered humanization approach allocates humanization effort based on the value of the page, not the volume of pages.
The tiered humanization framework
| Tier | Page type | Humanization treatment |
|---|
| Tier 1 | Top 50-100 highest-volume, highest-competition pages | Full API humanization + manual editorial pass |
| Tier 2 | Mid-volume category, hub, and second-tier market pages | Full API humanization + 10% QA spot-check |
| Tier 3 | Long-tail low-competition volume pages | Standard API humanization + automated engagement monitoring |
The tiering matters because it allocates quality effort efficiently. You're not spending the same resources on a page targeting a 20-search-per-month keyword as you are on a page targeting a 50,000-search-per-month keyword. The quality floor for Tier 3 pages only needs to be good enough to avoid triggering site-level quality signals. That's achievable with API humanization alone.
The Minimum Humanization Pass That Makes Pages Safe
If your budget or timeline only allows for one humanization pass per page, what does that pass need to accomplish? Four things:
- Eliminate the repetitive sentence structures that AI text produces at scale. AI has a tendency to write in parallel structures repeatedly — "X is important because Y. Z is also important because W."
- Add natural variation in sentence length. Mix short punchy sentences with longer ones.
- Ensure the unique data points in the page are naturally integrated into the prose, not just dropped in as statistics.
- Vary the opening sentences of paragraphs so they don't all start with the same grammatical construction.
A production-grade programmatic SEO pipeline that incorporates humanization has six distinct layers. Each layer has specific design requirements and common failure modes.
The six-layer production pipeline
| Layer | Function | Common failure mode |
|---|
| 1. Data source | Real entity-specific data for each page | Missing data fields silently produce thin pages |
| 2. AI generation | Prompt engineering with variation strategies | Same prompt × 10,000 entities = identical fingerprint |
| 3. Humanization | Batch API integration with concurrency | Failed API calls kill the batch without retry logic |
| 4. Automated QA | Word count, entities, reading level, duplicates | No QA means pipeline issues don't get caught |
| 5. Publishing cadence | Staggered over days instead of weekend dumps | 2,000 pages on Tuesday triggers early sampling |
| 6. Post-publish monitoring | Indexing, ranking, engagement per batch | Set-and-forget misses early quality signals |
Layer 1: Data Source Design
Your data source is the foundation. It determines the uniqueness of each page. Before you write a single template, ask: what data do I have that is specific to each entity and that cannot be found on a generic competitor page? Every variable that gets inserted into a page should come from your data source, not from AI generation. AI is for prose generation around the data. The data itself should be grounded in reality.
Layer 2: AI Generation Prompt Engineering
Prompts that ask for generic content produce generic content that needs heavy humanization. Prompts that force the AI to reference specific data points, use varied sentence structures, write from a specific perspective, and avoid the list of banned AI-writing patterns produce output that is closer to publishable quality before humanization even happens.
Prompt design principles:
- Include all the unique data points for the entity directly in the prompt so the model has to address them.
- Specify the tone, voice, and sentence structure style you want.
- Explicitly tell the model not to use generic filler language.
- Ask for a specific angle or perspective for each page type that forces differentiation from generic content.
- Use temperature settings that produce variation — don't use temperature 0 and wonder why all your pages sound identical.
Layer 3: Batch Humanization Processing
For batch processing at scale, you want asynchronous API calls with a concurrency limit that respects rate limits. A typical production setup might run 10-20 concurrent humanization requests, process a batch of 500 pages in 20-30 minutes, and log success, failure, and processing time for each request. Build your pipeline so it can be resumed from a checkpoint if it fails partway through.
Layer 5: Publishing Cadence That Doesn't Trigger Site-Wide Signals
Publishing 2,000 pages on a Tuesday afternoon is a flag. Not necessarily a penalty on its own, but it's the kind of behavior pattern that invites early sampling from Google's crawlers. Publishing 100 pages a day for 20 days produces the same 2,000 pages with a fraction of the risk. Staggered publishing also gives you rolling feedback.
Not all programmatic SEO has the same survival probability. Understanding which types survive and why saves you from investing in pipeline architecture for content categories that don't have a path to ranking.
Programmatic content types ranked by survival probability
| Content type | Survival condition | Failure pattern |
|---|
| Location pages | Real local data per location (neighborhoods, pricing, businesses) | Same text with city name swapped in |
| Comparison pages | Real feature tables, real pricing, opinionated analysis | Generic 'both tools offer strong features' filler |
| Directory pages | Each entity has unique, verified data | Thin listings that Google Maps already shows better |
| Keyword × category | Modifier actually filters real data differently | 'Cheap' and 'luxury' pages are essentially the same |
| Pure doorway pages | Never survive | Page adds nothing specific to its declared topic |
When pSEO Becomes Doorway Page Spam
The threshold is straightforward. If you could remove a page from your site and a user who arrived via that page would have been just as well served by being sent to your home page or a more general page, the page is a doorway page. If you build your programmatic content by asking "what does the person searching this actually need?" and then building pages that answer that question with real data, you're on the right side of the line. If you build by asking "which keywords can I intercept?" without caring about the answer content, you're building a penalty.
ℹ️The survival test for programmatic pages
Print out any five random pages from your programmatic batch. Hand them to someone who doesn't know your site. Ask if each page told them something specific and useful about the topic it claimed to be about. If three or more of the five get a "not really," your pages need more data and better humanization before they're ready to publish.
If you're reading this after the fact — after a Helpful Content Update has already hit your site — this section is for you. Recovery is possible. It is not fast. It is not guaranteed. But there is a methodical approach that gets sites back to ranking.
Page-Level vs Site-Level Penalties
A page-level quality issue affects the ranking of individual pages that Google has evaluated as low quality. A site-level Helpful Content signal affects the ranking potential of your entire domain. The way to tell the difference: if your high-quality, well-researched pages that have earned backlinks and have good engagement signals also dropped significantly in rankings, you have a site-level signal. If only the thin programmatic pages dropped, you have a page-level issue.
Site-level signals are harder to recover from because improving individual pages is not enough. You need to change the ratio of helpful to unhelpful content across the whole domain.
Noindex vs Delete vs Humanize Decisions
For each page in your penalized programmatic batch, you need to make one of three decisions:
- Humanize and improve: Pages where you have good underlying data, the template is sound, and the issue is primarily content quality. Fix them.
- Noindex: Pages where the data is thin but the URL might have some indexed presence or backlinks. Remove them from Google's quality calculation without the deletion being a signal itself.
- Delete: Pages where there's no underlying data worth salvaging, the URL has no value, and there's no reasonable path to making them genuinely useful. Delete them and redirect to a more useful page.
Reconsideration Request Timing
A note on reconsideration requests: they're for manual actions, not algorithmic penalties. The Helpful Content system is algorithmic. Filing a reconsideration request for an HCU penalty does nothing because there's no manual reviewer who issued the penalty. What you're waiting for is the next core update. This is why recovery takes six to eighteen months even when you do everything right.
⚠️Mistake 1: Treating humanization as a detection bypass tool
Teams set up their programmatic pipeline with AI content, then add a humanization step specifically to bypass AI detection tools. They test in GPTZero, see "low AI probability," and consider the work done. Passing an AI detector is not the same as passing Google's quality evaluation. A page can be undetectable by AI detectors while still being completely hollow from a quality perspective.
⚠️Mistake 2: Humanizing without fixing the underlying data problem
You cannot humanize your way out of a data problem. If your page about "electricians in Omaha" contains zero Omaha-specific data points, humanizing the prose produces nothing dressed differently. The data layer has to exist before humanization can do its job.
⚠️Mistake 3: Using the same prompt for 10,000 pages with no variation
Running the same generation prompt 10,000 times with only the variable data changing produces 10,000 pages with the same structural and stylistic fingerprint. Even after humanization, the underlying DNA signals template content. Use multiple prompt variants, conditional logic for different entity sizes, and temperature settings that produce real variation.
⚠️Mistake 4: Publishing the entire batch at once
Publishing 5,000 pages in a single weekend is a flag that invites early scrutiny. Even if every page passes quality evaluation individually, the velocity of publishing triggers aggressive sampling. Stagger over days or weeks.
⚠️Mistake 5: Not testing the template before scaling
The most expensive mistake. 3,000 pages get generated and published without a test run. Six weeks later the template has a structural flaw that affects the whole batch. At 3,000 pages, fixing that is a massive undertaking. At 50 pages, it's a quick iteration. Always run a 20-100 page test batch first.
⚠️Mistake 6: Ignoring post-publish signals
Set-and-forget misses the early warning signals that indicate quality problems before they accumulate into a site-level issue. Set up batch-level monitoring dashboards that track indexing rate, average position, and click-through rate for each publishing batch distinctly.
⚠️Mistake 7: Humanizing only the first paragraph
Some teams run humanization on just the intro paragraph because it's the most visible part. The rest remains obviously AI-generated template text. Google evaluates the full page. Run humanization on complete page text, not just the opening.
⚠️Mistake 8: Over-keyword-stuffing after humanization
Manually stuffing target keywords into humanized text creates an inconsistency pattern — natural prose interrupted by awkward keyword insertions — that is detectable as manipulation. Keyword integration should happen at the generation stage, naturally built into the content brief.
⚠️Mistake 9: Not accounting for content freshness
Programmatic pages often contain time-sensitive data — prices, ratings, statistics. Stale data that contradicts real-world facts sends negative engagement signals. Build update cycles into your programmatic content management.
⚠️Mistake 10: Building without an internal link architecture
Orphaned programmatic pages with no internal links signal a spam pattern. Your programmatic pages should be part of your site's information architecture — category pages linking to entity pages, entity pages linking to related entities, main navigation including entry points to programmatic sections.
The Pipeline
Define your entity set and keyword universe
Identify the entities your programmatic pages will cover and map the keyword patterns they target. Use Ahrefs or Semrush to validate real search demand. Build a spreadsheet mapping each entity to its keyword targets and estimated search volume.
Build and validate your data layer
For each entity, compile the unique data points that will differentiate each page. Scrape verified business data, purchase datasets, run surveys, or aggregate public data from official sources. The data layer is the foundation of page quality. Every hour spent here reduces humanization burden downstream.
Design your data schema
Structure your entity data in a schema that maps cleanly to your template variables. Document which fields are required (page fails without them) vs optional. This discipline prevents template generation from silently producing low-quality pages when a field is empty.
Write your generation prompts
Design prompts that produce genuinely varied, data-grounded output. Include all unique data fields in the prompt. Specify tone, voice, and structural style. Explicitly prohibit generic filler language. Write multiple prompt variants and plan to rotate them.
Run a small generation test
Generate 50-100 pages from your initial prompt design. Read 10 carefully. Would a real person find it genuinely useful? Does each page feel specifically about its named entity or just generally about the topic category? If not, revise before scaling.
Set up your humanization API integration
Build the API integration layer: client code, batch processing with concurrency limits, error handling and retry logic, logging for every API request and response. Test with a small batch before scaling.
Run humanization on your test batch
Process your 50-100 test pages through the humanization layer. Read 10 humanized outputs side by side with the raw versions. The humanized version should read noticeably more naturally, with more variation in sentence structure and length.
Build your automated QA layer
Write automated quality checks: word count validation, reading grade level distribution, entity presence verification, duplicate sentence detection across batches, and basic AI pattern checks. Set up a review queue for pages that fail any check.
Publish your test batch
Publish the 50-100 page test batch to your live site. Submit the sitemap update. Check Search Console daily for two weeks, then weekly for six weeks. Track indexing rate, ranking appearances, and early click data.
Evaluate test batch results
After 30-60 days, evaluate. Indexing rate above 80% is good. Ranking appearances within 30 days is good. If indexing is below 60%, you have a quality signal problem that needs diagnosis before scaling.
Scale with staggered publishing
Schedule publishing in daily batches that match a cadence you can monitor. 100-200 pages per day is a reasonable starting cadence. Watch Search Console metrics daily during the initial scaling period. Pause and investigate if indexing rates drop below your test batch baseline.
Build your monitoring and update cycle
Monthly review of indexing rates, ranking positions, and engagement per batch. Quarterly review of data freshness. Annual review of template and prompt design to ensure it still reflects current best practices.
Case Studies
Scenario 1: Travel Site Building Destination Guides
A travel comparison site decides to build programmatic destination guides for 3,000 cities.
The failing version: They generate all 3,000 pages from a single prompt template asking the AI to write a 500-word guide about each city. The output reads like a Wikipedia summary written by someone who has never been to any of these places. Every page mentions "a vibrant culture" and "a variety of dining options" and "attractions for every type of traveler." After publishing, 60% of the pages don't get indexed. The 40% that do don't rank. Six weeks later, the site gets a Helpful Content signal that affects its entire domain.
The working version: They spend two weeks building a data layer. They scrape real attraction data from TripAdvisor for each city, including actual attraction names and review counts. They pull real weather data by month from weather APIs. They buy a tourism dataset with real visitor counts by season. They pull real hotel price ranges from booking data. Now the prompt for each city is loaded with real city-specific data. The pages humanize cleanly because the underlying content already has character. After a 100-city test batch shows strong indexing and early ranking movement, they scale to 3,000 over six weeks. Site-level quality signals stay positive.
Scenario 2: SaaS Comparison Site
A SaaS discovery platform builds comparison pages for every combination of tools in their database — potentially 50,000+ pages.
The failing version: Generic commentary with placeholder text. "Both tools offer strong collaboration features with different approaches to workflow management." The written sections add nothing to the feature data. Google classifies the written portions as thin and the pages don't rank despite having real feature data in the tables.
The working version: They redesign their prompt to require the AI to make actual arguments from the feature data. For each comparison, the prompt gets the feature table and is instructed to write the prose as an opinionated analysis: which tool is stronger for which use case, what the key differentiator is, who should not choose each tool. The pages start getting cited in Reddit threads and Quora answers because they actually help people decide. That earned engagement signal pushes them into strong ranking positions.
Scenario 3: Local Services Site
A home services lead generation platform builds 45,000 pages for queries like "roof repair 90210" and "HVAC installation Denver CO."
The failing version: Pages essentially identical for the same service across ZIP codes. The only thing that changes is the ZIP code and city name in the template. The pages don't index. The ones that do don't rank. And the sheer volume of thin pages tanks the site's quality signal for core conversion pages.
The working version: They segment 50 metro areas into three tiers by traffic potential. Top-tier metros get a premium treatment: real contractor listings pulled from licensing databases, real permit data showing contractor activity, real review aggregation, real pricing data from market research. These pages are 1,200-word guides. Mid-tier metros get moderate treatment. Bottom-tier markets get the minimum viable data treatment. This tiered approach means the 15% of pages targeting the highest-value markets are genuinely excellent, which supports the site-level quality signal and allows mid-tier pages to rank on that foundation.
Pipeline tool stack summary
| Layer | Category | Key requirement |
|---|
| Data layer | Public APIs, purchased datasets, scrapers | Entity-specific, verified, current data |
| Generation | GPT-4o, Claude Sonnet | Large context window, prompt variation support |
| Humanization | Humanization API (e.g. HumanLike.pro) | Batch API access, structural variation output |
| QA | Custom scripts, Originality.ai API | Automated checks before publish |
| CMS | Sanity, Contentful, custom | Programmatic publishing, incremental builds |
| Monitoring | Search Console, Ahrefs | Batch-level indexing and ranking tracking |
For API-based batch humanization, you need a tool that is built for programmatic use, not just consumer paste-and-click. HumanLike.pro provides an API specifically designed for this kind of pipeline work — you call it with your generated text and receive humanized output that changes the structural and stylistic patterns of the content while preserving the meaning and the specific data points you've included. At scale, this becomes a core infrastructure component rather than an add-on step. The key feature to look for in any humanization API is that it produces genuine structural variation, not just synonym substitution.
You have the full picture. You know what kills programmatic SEO content — thin data, template uniformity, no humanization, batch publishing, no monitoring. You know what saves it — genuine data layers, tiered quality effort, API humanization, staggered publishing, and post-publish feedback loops that catch problems early.
If you are planning a new programmatic SEO build, start with the data layer. Before you write a single template or prompt, verify that you have genuinely unique data for each entity you're targeting. A list of city names is not a data layer. City names plus demographics plus local business data plus real pricing ranges is a data layer. Build that first. Then design the pipeline around it.
If you have an existing programmatic build that is working right now, add humanization to your pipeline before the next update cycle. Don't wait for the penalty. The cost of adding humanization to a working pipeline is trivial. The cost of rebuilding after a site-wide quality signal hit is not.
If you've already been hit, triage first. Pull your pages by traffic value, identify which ones have salvageable data underlying them, start the humanize-and-improve track on your top 20% by traffic potential. Noindex the bottom tier. Wait for the next core update and measure. This is not a 30-day fix. It is a 6-month rebuild.
💡Your first action this week
Pick 10 random pages from your existing programmatic content. Read them out loud. Would you share any of them with someone who actually needed that information? If the honest answer is no for most of them, that's your starting point. The data layer review and humanization pipeline are the next step from there.
The teams winning at programmatic SEO in 2026 built real pipelines
They're not winning because they found a Google loophole. They're winning because they built real pipelines with real data, genuine humanization, and actual quality checks. Programmatic SEO at scale is still one of the highest-leverage content strategies available — but only for the teams who do the unglamorous work of data layers, tiered humanization, and batch-level monitoring.